Gecko: a fast GLR parser with automatic syntax error recovery
Gecko: A Fast, Standalone GLR Parser Library in C
Parsing is the backbone of every programming language implementation, and the choice of parser technology has far-reaching consequences for the language designer. LALR(1) parsers like YACC and Bison have dominated for decades, but they force grammar authors into contortions to avoid conflicts. Generalized parsers – those that handle the full class of context-free grammars, including ambiguous ones – have traditionally been considered too slow for production use.
Gecko is a new GLR parser library that challenges that assumption. It handles any context-free grammar, provides automatic syntax error recovery with no grammar modifications, and still runs at speeds competitive with YACC on unambiguous grammars.
In this post I’ll walk through Gecko’s design goals, its key features, how to use it in your own projects, and the benchmarks that demonstrate its performance.
Why another parser?
The world of parser generators is crowded. YACC and Bison have been around since the 1970s. More recently, PEG parsers, parser combinators, and various Earley-based tools have appeared. So why build yet another parser?
During my career I wrote several compiler-compilers. The first one was an LALR(1) parser written in 1985 in Pascal (you can try to find its description in the Russian journal “Programming” for 1985). The next one was MSTA, written in the nineties. It was an LALR(k)/LR(k) parser with many additional optimizations that made it faster than YACC/Bison. Using it I found that speed is not the most important feature of a parser, especially with faster modern CPUs, and that LR(k) is not enough for real language grammars.
Therefore, about ten years ago I wrote YAEP: an Earley parser that can work with any context-free grammar. I spent a lot of time making it fast, and it is actually the fastest implementation of an Earley parser that I know of. Still, I was not satisfied with its speed and memory consumption for unambiguous and moderately ambiguous grammars. Unfortunately, it is difficult to solve these problems because of inherent features of the Earley algorithm. Therefore, recently I turned my attention to GLR parsers – and Gecko is my implementation of one.
I don’t know tools that offer the combination of features that Gecko provides:
- Full CFG support – no restrictions on grammar structure, including ambiguous grammars
- Library form – embeddable in any C program, with no external code generation step
- Operator precedence/associativity –the same mechanism that YACC users have relied on for decades
- Automatic error recovery –no
errortokens, no grammar modifications, just correct parse trees with minimal token skipping - Competitive speed –within 5–10% of YACC on unambiguous grammars, and dramatically faster than other GLR parsers on ambiguous ones
Let’s look at each of these in detail.
Feature overview
Small and simple
Gecko core code is roughly 2800 lines of C (SLOC). It uses 6 header-only utility libraries (custom allocators, bitmaps, hashing, hash tables, variable-length objects, and object stacks) which is about 900 lines. So Gecko’s entire implementation is roughly 3,700 lines of C (SLOC). The compiled x86-64 code weighs in at about 90KB. There are no external dependencies beyond the C standard library. This makes Gecko trivial to embed in any project –just drop in the source files and compile.
Full context-free grammar support
YACC and Bison are limited to LALR(1) grammars. Bison claims GLR
support, but I was unable to make it work with ambiguous grammars.
Using %glr-parser with an ambiguous C grammar (the same one used by
Gecko and ElkHound for
benchmarking) reports a syntax error on the third line. With the
simplest ambiguous grammar E : E '+' E | 'a' it reports a syntax
error on the 23rd token.
Gecko, by contrast, can parse inputs described by any context-free
grammar, including ambiguous ones. This is particularly useful for
languages like C, where the infamous “typedef problem” (is T * x; a
pointer declaration or a multiplication?) creates genuine ambiguity if
typenames are not distinguished from identifiers at the lexer level.
With Gecko, you can use a single token type for all identifiers – including typenames –and let the parser explore both interpretations simultaneously. The ambiguity is resolved structurally in the resulting parse tree, rather than requiring feedback hacks between scanner and parser.
Simple syntax-directed translation
Gecko doesn’t use semantic actions the way YACC does. Instead, it generates abstract syntax trees (ASTs) as output using a concise notation in the grammar rules. Each rule’s right-hand side can specify which children contribute to the AST node:
E : T # 0
| E '+' T # plus (0 2)
;
T : F # 0
| T '*' F # mult (0 2)
;
F : 'a' # 0
| '(' E ')' # 1
;
The # notation after each alternative specifies the translation:
# 0means “the translation of this rule is the translation of RHS symbol at index 0” (i.e., pass through)# plus (0 2)means “create an abstract node namedpluswhose children are the translations of RHS symbols at positions 0 and 2”# 1means “the translation is the translation of the RHS symbol at index 1” (skipping the left parenthesis)
This approach is simpler than YACC-style actions for many use cases:
you get a clean AST without writing any C code in the grammar. The
resulting parse tree consists of GP_TERM nodes (for terminals),
GP_ANODE nodes (for abstract nodes with named children), GP_NIL
nodes (for empty translations), GP_ALT nodes (for ambiguous
alternatives), and GP_OPT nodes (for context-dependent
alternatives).
For the grammar above and input a+a*(a*a+a), Gecko will generate the
following tree:
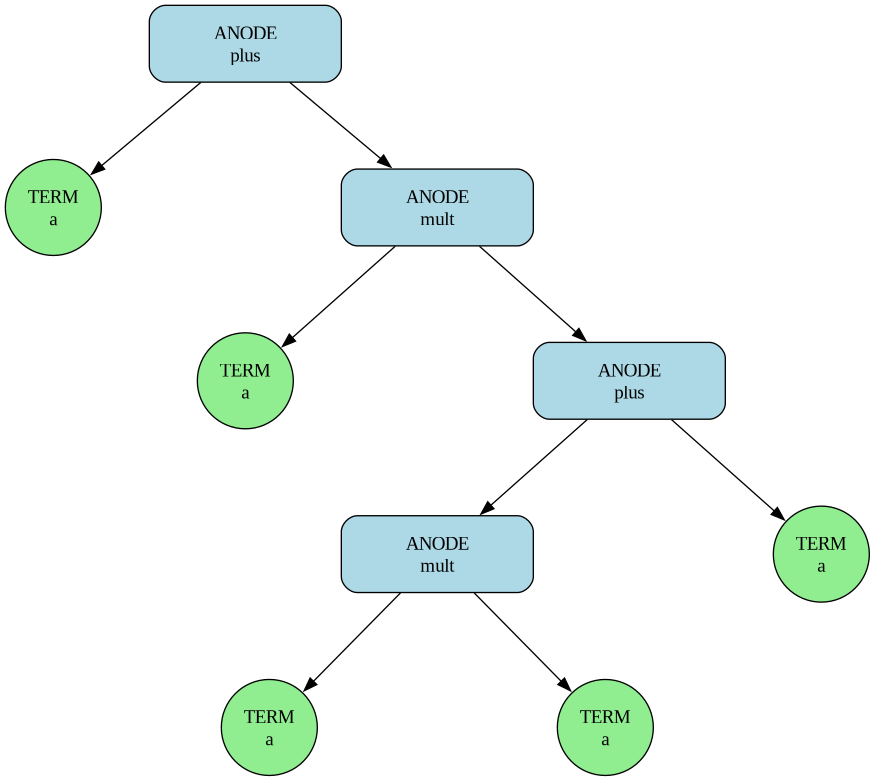
In the tree, ANODE and TERM represent parse tree node types
(GP_ANODE and GP_TERM), plus and mult are the name field of
the abstract node, and a represents the attribute of the corresponding input
token.
Operator grammars
Many practical grammars include expression syntax with dozens of precedence levels. Writing these out as a cascade of nonterminals (one per precedence level) is tedious and error-prone. Gecko supports operator priority and associativity declarations using the same syntax as YACC/Bison:
LEFT '+';
LEFT '*';
E : 'a' # 0
| '(' E ')' # 1
| E '+' E # plus (0 2)
| E '*' E # mult (0 2)
;
Here, LEFT '+' and LEFT '*' declare left-associative operators
with * having higher precedence than + (later declarations have
higher precedence). This lets you write ambiguous-looking rules like
E '+' E and have Gecko resolve the conflicts the same way YACC
would. The full power of GLR parsing is still behind it in case other
parts of your grammar are genuinely ambiguous.
The supported associativity declarations are LEFT, RIGHT, and
NONASSOC, and multiple tokens can appear on the same line to share a
precedence level.
As with YACC, writing grammars that use operator precedence/associativity declarations and left-recursive rules results in faster parsing and lower memory consumption.
Library architecture
Gecko is a library, not a standalone tool. This is a fundamental design
decision. Where YACC and Bison generate C source files that you compile and
link, Gecko is simply linked into your program. The grammar can be provided
either through function calls (gp_read_grammar) or as a YACC-like
description string (gp_parse_grammar).
This means:
- No code generation step in your build process
- Multiple grammars can coexist in the same program
- Grammars can be changed at runtime –read from configuration files, constructed dynamically, or switched between parsing passes
- Very fast startup after reading a grammar from a file or string
The core API is deliberately minimal:
struct grammar *g = gp_create_grammar();
gp_parse_grammar(g, true, description);
gp_parse(g, read_token, &root, &ambiguity, NULL);
gp_fin(g);
Four function calls to go from grammar description to parse tree.
Automatic syntax error recovery
This is perhaps Gecko’s most distinctive feature. People who have used YACC/Bison or other widely used compiler-compiler tools know how difficult it is to implement good syntactic error recovery. In my experience, more time is spent on this task –and on dealing with syntax errors in the semantic checker –than on writing the original grammar. Therefore, a strong emphasis in the Gecko project was placed on simplifying this task.
Syntax error recovery in Gecko is automated as much as possible. Gecko always generates parse trees corresponding to some correct input, which is obtained from the original erroneous input by removing as few tokens as possible.
Traditional parser generators require you to manually add error tokens to
your grammar to enable any kind of error recovery. Getting this right is
notoriously difficult –place the error token in the wrong production
and the parser either gives up too early, or swallows too many tokens and
produces confusing follow-on errors.
Gecko’s error recovery is fully automatic. It requires no grammar modifications whatsoever. This is made possible by Gecko’s GLR architecture, which naturally maintains multiple parsing stacks simultaneously.
How it works
When a syntax error is detected (a token that no current stack can shift or reduce on), Gecko’s recovery algorithm kicks in:
-
Reject and pop. For each failed stack, Gecko rejects the current stack token and creates a new stack derived from the failed stack by popping the top elements until the new stack has an action on the current token of the original stack.
-
Find minimal-cost success. Recovery succeeds when a candidate stack with minimal cost successfully consumes a configurable number of consecutive tokens (default: 5, can be changed via
gp_set_recovery_match) without encountering another error, or when a candidate reaches EOF. -
Resume normal parsing. All stacks that matched at least one token become the new starting point for continued parsing.
The key guarantee
Gecko’s error recovery guarantees that the parser always produces parse trees corresponding to syntactically correct inputs. The way it achieves this is conceptually simple: some tokens before and/or after the error point are ignored, and the remaining token stream is syntactically valid according to the grammar. The parser reports which tokens were involved in the error through a user-configurable error callback.
Consider a simple expression grammar (see section “simple syntax-directed translation” above)
and the input a+a*(a*+a) –note the
extra * before +a). Gecko will detect the error at the + token (after
a*), determine that skipping the second * operator yields a valid continuation,
and produce a parse tree as if the input had been a+a*(a+a). The error
callback reports the problematic tokens, and parsing continues.
This approach works well in practice because:
- It is grammar-agnostic –any grammar gets error recovery for free
- It finds the minimal-cost repair, not just any repair
- It handles multiple errors in the same input, recovering from each one independently
- The parse tree output is always structurally valid
Note that minimal-cost error recovery here means minimal within a
local search space. I am not aware of any parser that searches for a
globally minimal-cost error recovery. For example, YAEP performs a
global search only in a limited sense: it minimizes the number of
tokens covered by the special grammar terminal error.
The grammar description language
Gecko accepts grammars in a YACC-like textual format via gp_parse_grammar.
The format supports:
Terminal declarations
Named terminals with explicit codes are described as follows:
TERM IDENTIFIER = 300 CONSTANT = 338 STRING_LITERAL = 340;
Multiple terminals can be declared in a single TERM statement, each with
an optional = code assignment.
Single-character literals ('a', '+', etc.) are terminals with
codes equal to their ASCII values and should not be described in TERM
declarations.
Operator precedence
LEFT '+' '-';
LEFT '*' '/' '%';
RIGHT ELSE;
NONASSOC '<' '>';
Operators listed on the same line share a precedence level. Lines appearing later have higher precedence. This is identical to YACC/Bison semantics.
Rules
lhs : rhs_symbol_1 rhs_symbol_2 ... # translation
| alternative_rhs ... # translation
;
Terminals can be single-character literals ('a', '+') or named tokens
(IDENTIFIER). Nonterminals are any names not previously declared as
terminals.
Gecko requires the grammar axiom (start symbol) to have exactly one rule.
Therefore, when using gp_read_grammar, you typically add an explicit
start rule such as $S : E that has a single alternative (see programmatic grammar construction). When using
gp_parse_grammar, Gecko adds such a rule automatically.
Translation specifications
After #:
- A single number
Nmeans the translation is the translation of the Nth RHS symbol (0-indexed) name (i j k)creates an abstract node with the given name whose children are the translations of RHS symbols at positions i, j, k- Omitting the
#gives a nil translation
An optional guard can follow the translation: ? N assigns guard
number N to the rule alternative (see Rule Guards in Configuration).
Comments
C-style /* ... */ comments are supported in grammar descriptions.
Programmatic grammar construction
For maximum flexibility, Gecko also supports building grammars
programmatically via the gp_read_grammar function. You provide two callback
functions:
read_terminal –called repeatedly to provide terminal definitions:
const char *read_terminal(int *code, int *priority, enum gp_assoc *assoc) {
// Return terminal name, set code, priority, and associativity.
// Return NULL when done.
}
read_rule –called repeatedly to provide grammar rules:
const char *read_rule(const char ***rhs, const char **abs_node, int **transl,
int *guard_num) {
// Return LHS name, set RHS array, abstract node name, translation,
// and guard number. Return NULL when done.
}
Assume we have a simple expression grammar:
LEFT '+';
E : 'a' # 1
| E '+' E # plus (0 2)
| '(' E ')' # 1
;
A complete example of programmatic grammar construction for the grammar would be
static int nterm = 0;
const char *read_terminal(int *code, int *priority, enum gp_assoc *assoc) {
nterm++;
*priority = -1; *assoc = GP_NON_ASSOC;
switch (nterm) {
case 1: *code = 'a'; return "a";
case 2: *assoc = GP_LEFT_ASSOC; *code = '+'; return "+";
case 3: *code = '('; return "(";
case 4: *code = ')'; return ")";
default: return 0;
}
}
static int nrule = 0;
const char *read_rule(const char ***rhs, const char **anode, int **transl,
int *guard_num) {
typedef const char *str;
nrule++;
*guard_num = -1; *anode = 0;
switch (nrule) {
case 1: *rhs = (str[]){"E", 0}; *transl = (int[]){0, -1}; return "$S";
case 2: *rhs = (str[]){"a", 0}; *transl = (int[]){0, -1}; return "E";
case 3: *anode = "plus"; *rhs = (str[]){"E", "+", "E", 0};
*transl = (int[]){0, 2, -1}; return "E";
case 4: *rhs = (str[]){"(", "E", ")", 0}; *transl = (int[]){1, -1}; return "E";
default: return 0;
}
}
This programmatic interface is useful when grammars need to be constructed dynamically or when integrating Gecko with a system that already has its own grammar representation.
A complete usage example
Here is a small but complete example showing how to use Gecko to parse arithmetic expressions:
#include <stdio.h>
#include <stdlib.h>
#include <stddef.h>
#include "gecko.h"
#define NUMBER 300
static const char *description =
"\n"
"TERM NUMBER = 300;\n"
"LEFT '+';\n"
"LEFT '*';\n"
"E : E '+' E # plus (0 2)\n"
" | E '*' E # mult (0 2)\n"
" | '(' E ')' # 1\n"
" | NUMBER # 0\n"
" ;\n"
;
static struct { int code; int val; } input[] = { /* Input: 10 + 2 * (5 + 11) */
{NUMBER, 10}, {'+', 0}, {NUMBER, 2}, {'*', 0}, {'(', 0},
{NUMBER, 5}, {'+', 0}, {NUMBER, 11}, {')', 0}
};
static int input_pos = 0;
static int read_token_func(void **attr) {
if (input_pos >= (int)(sizeof(input) / sizeof(input[0]))) return -1;
*attr = (void *)(ptrdiff_t)input[input_pos].val;
return input[input_pos++].code;
}
int main(void)
{
struct grammar *g; struct gp_tree_node *root; int ambiguity;
if ((g = gp_create_grammar()) == NULL) {
fprintf(stderr, "gp_create_grammar: No memory\n"); exit(1);
}
if (gp_parse_grammar(g, true, description) != 0) {
fprintf(stderr, "%s\n", gp_error_message(g)); exit(1);
}
gp_set_debug_level(g, 2);
if (gp_parse(g, read_token_func, &root, &ambiguity, NULL))
fprintf(stderr, "gp_parse: %s\n", gp_error_message(g));
gp_fin(g);
return 0;
}
Build the example with
gcc -O2 -I/usr/local/include example.c /usr/local/lib/libgecko.a
A few things to note:
-
gp_create_grammar()allocates and initializes the grammar object. -
gp_parse_grammar(g, true, description)parses the textual grammar description. Thetrueargument enables strict grammar checking (detecting unreachable nonterminals, nonterminals that can’t derive terminal strings, loops, etc.). -
gp_set_debug_level(g, 2)enables printing of the result translation (AST) to stderr, which is useful for verifying the parse tree structure. -
gp_parse(g, read_token_func, &root, &ambiguity, NULL)runs the parser.read_token_funcis a user-provided function that returns the next token’s code and attribute. It returns a negative value at end of input. On success,rootpoints to the parse tree andambiguityindicates the ambiguity level. 0 means no ambiguity. 1 means the grammar is found to be ambiguous on the input. 2 means the final stack was produced by merging stacks where terminal attributes or abstract nodes differed, which would result in context-dependent alternative (GP_OPT) nodes in the parse tree if a custom merge function is provided. The last argument is passed to the rule guard function (see below). -
gp_fin(g)frees all resources associated with the grammar. -
/usr/localis the default directory where Gecko is installed bymake install.
Configuration and customization
Gecko provides several configuration functions to customize parser behavior:
Memory management
gp_set_parse_alloc(g, my_alloc); // Custom allocator for parse tree nodes
gp_set_parse_free(g, my_free); // Custom deallocator (NULL = no freeing)
By default Gecko uses malloc and free. You can provide custom
allocators, for instance to use arena allocation for the parse tree.
Note that it is not safe to change these functions after gp_parse and
before gp_fin, as some data allocated by parse_alloc in gp_parse
can be freed in gp_fin and when reading a new grammar.
Syntax error reporting
gp_set_syntax_error(g, my_error_func);
The error function receives the representation of a nonterminal
related to the error position and a boolean after_p flag indicating
whether the error occurred after that nonterminal (print “error
after …”) or within it (print “error in …”). It also receives the
representation and attribute of the error token, plus the
representation and attribute of the token where recovery stopped.
The default function prints the error nonterminal and token
representations. In a real compiler, you would set this to print file
names, line numbers, and column numbers extracted from the token
attributes. You would also translate nonterminal names into more
readable form (e.g., nonterminal stmt used in grammar into statement).
Error recovery tuning
gp_set_recovery_match(g, 7); // Require 7 matched tokens for recovery
The default is 5. Higher values produce more conservative recovery (fewer false recoveries, but potentially more tokens skipped). The optimal value depends on your grammar and expected input.
Debug output
gp_set_debug_level(g, 3);
Debug levels range from 0 (silent) to 6 (extremely verbose):
- Level 1: Statistics (number of SLR sets, parse tree nodes, etc.)
- Level 2: Additionally print the result translation (AST)
- Level 3: Print read tokens, SLR set actions and conflicts, and high-level error recovery information
- Level 4: Print grammar rules, FIRST/FOLLOW sets, and all generated SLR sets
- Level 5: Print stack operations during parsing and stack merging
- Level 6: Even more detailed stack processing information
Rule guards
gp_set_rule_guard(g, my_guard);
Rule guards allow you to reject specific rule reductions during
parsing, enabling context-sensitive parsing constraints. Each rule
alternative can have a guard number assigned in the grammar
description (using ? N after the translation) or via read_rule.
When a rule with a guard number is about to be reduced, the guard
function is called with that number and the arg passed to
gp_parse. If the guard function returns false, the reduction is
rejected.
The guard function can also prepare data for subsequent guard calls. For example, using this mechanism you could distinguish typenames from identifiers in a C grammar, eliminating the need for ambiguous parsing and generation of alternative nodes.
Stack merging for ambiguous grammars
ElkHound uses a mechanism to merge different translations of merged stacks. Gecko uses an analogous mechanism, but with a more explicit interface.
gp_set_node_merge_func(g, my_merge);
When the parser merges stacks (because two parsing paths have reached the same state), it needs to combine the parse tree nodes from both paths. The default merge function simply returns the first node, effectively choosing one arbitrary parse.
If you want to preserve all alternatives (e.g., for later semantic
disambiguation), you can use gp_get_alt_node and
gp_get_opt_node:
void *my_merge(struct grammar *g, struct gp_tree_node *node1,
struct gp_tree_node *node2, size_t context_num) {
return context_num == 0 ? gp_get_alt_node(g, node1, node2)
: gp_get_opt_node(g, node1, node2, context_num);
}
This creates GP_ALT or GP_OPT nodes in the parse tree that
represent all possible interpretations. The context_num argument
defines the merge context. A zero value indicates a
context-independent alternative. A positive value indicates
correlated alternatives –in such cases, GP_OPT
(context-dependent alternative) nodes should be used instead of
GP_ALT to preserve the correct pairing of alternatives (see the
parse tree section below for details).
The parse tree
Gecko’s parse tree is a tree of struct
gp_tree_node values. Each node has a type field and a num field
(a unique node number), plus a C union containing the type-specific
data:
GP_NIL–an empty node, used for empty translationsGP_TERM–a terminal node, containing the terminalcodeand user-providedattrGP_ANODE–an abstract node, containing anamestring and an array ofchildren(each a pointer to anothergp_tree_node)GP_ALT–an alternative node (for ambiguous grammars), containingfirstandsecondpointers to two alternative parse treesGP_OPT–a context-dependent alternative (option) node, containing acontext_num,first, andsecond. UnlikeGP_ALT, option nodes indicate that the alternatives are correlated with other option nodes having the samecontext_num. For example, when merging stacks...a...b...and...c...d..., usingGP_ALTnodes would produce...alt(a,c)...alt(b,d)..., which incorrectly implies four combinations (ac,ad,bc,bd) instead of the two correct ones (ac,bd).GP_OPTnodes preserve this correlation:...opt(n,a,c)...opt(n,b,d)..., wherenis some context number.
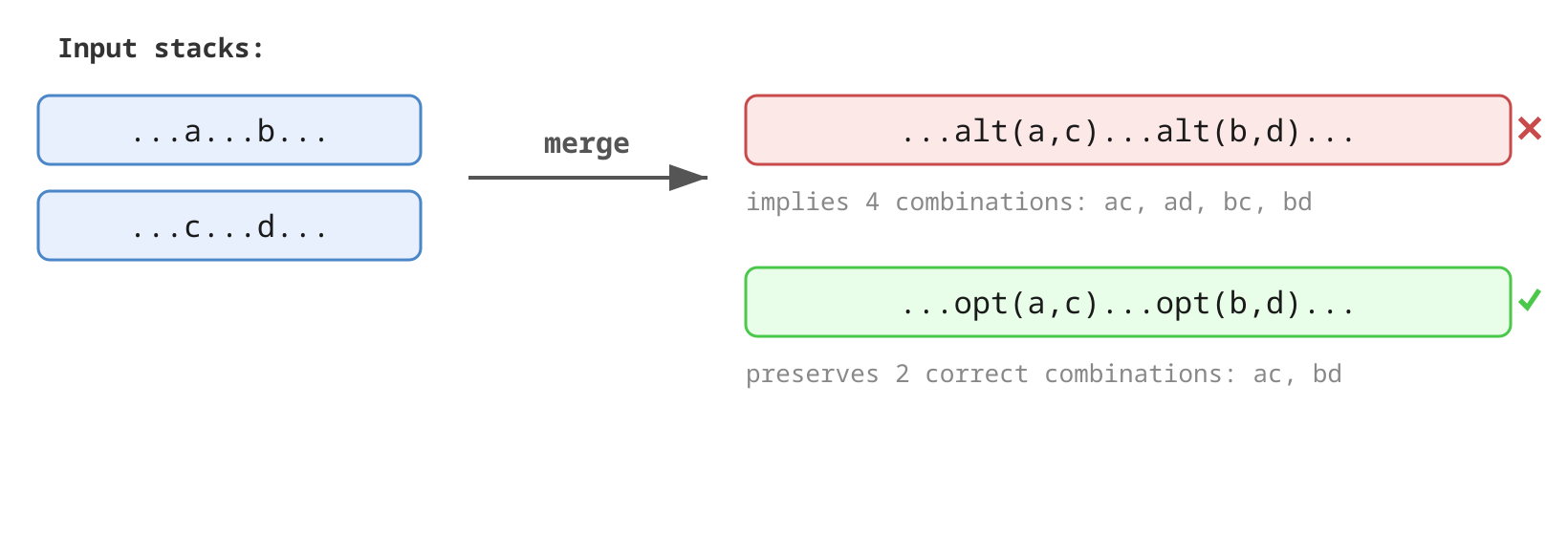
Fortunately, this is a rare case for programming language grammars; for example, the C grammar does not exhibit this behavior.
To correctly traverse the parse tree, you should always choose the
same alternative (first or second) for option nodes with the same
context_num. By doing so, it is possible to eliminate option nodes
and transform the parse tree to contain only context-independent alternative nodes, but
this is a non-trivial task. If your grammar requires this, consider
using YAEP, which handles this
automatically.
The parse tree can be very
unbalanced, so using recursive functions for traversal may cause stack
overflow. Gecko provides gp_traverse_tree, which uses an explicit
stack instead of recursion. It calls user-provided preorder and
postorder functions before and after processing each node’s
children. If the preorder function returns false, the node’s
children are skipped. Both callbacks receive the current node, its
parent, and a user-provided argument.
You can free the parse tree explicitly with:
gp_free_tree(g, root);
Or, if you provided a custom parse_free function, all parse tree memory
will be freed through that. Setting parse_free to NULL disables
automatic freeing entirely, which is useful if you’re using arena allocation
and plan to free everything at once.
Comparison with other parser technologies
Here is a summary of how Gecko compares with the major alternatives:
| YACC | Bison | ElkHound | YAEP | Gecko | |
|---|---|---|---|---|---|
| Library | No | No | No | Yes | Yes |
| CFG grammar | LALR(1) | LALR(1) | Ambiguous | Ambiguous | Ambiguous |
| Operator grammar (priority/associativity) | Yes | Yes | Yes | No | Yes |
| Speed independent of grammar size | Yes | Yes | Yes | No | Yes |
| Syntax error recovery | Yes | Yes | No | Yes | Yes |
| Automatic error recovery | No | No | – | No | Yes |
| Actions | Yes | Yes | Yes | No | Yes* |
| Simple syntax-directed translation | No | No | No | Yes | Yes |
| Generation of all translations | – | – | Yes | Yes | Yes |
| Generation of minimal cost translation | – | – | No | Yes | No |
| Reentrant (thread-safe) | Yes** | Yes** | Yes | No | Yes |
(*) See rule guard functions.
(**) Needs non-POSIX extensions %pure-parser or %define api.pure.
Key differentiators:
- Gecko and YAEP are the only libraries –everything else requires a separate code generation step
- Gecko is the only parser with automatic error recovery –all others require manual grammar modifications
- YAEP is the only parser without operator grammar support
- YAEP can generate minimal-cost translations for ambiguous grammars, which Gecko doesn’t support. YAEP is also faster when generating all possible translations for highly ambiguous grammars
Benchmark results
Performance claims are meaningless without data. Gecko includes a
comprehensive benchmark suite (make bench) that compares it against
YACC,
ElkHound (a well-known GLR
parser), and YAEP (a fast Earley
parser).
Test setup
The benchmarks use an ANSI C grammar as the test grammar. For Gecko, ElkHound, and YAEP, the grammar is slightly ambiguous because typenames use the same token type as identifiers. For YACC, typenames are a separate token type (since YACC can’t handle the ambiguity).
Two test files are used:
- 1.5 million lines of C code (100,000 sieve functions)
- 500,000 lines of C code (an old version of GCC, all files combined)
Parsing time includes scanning time, but I found that even for the fastest parsers scanning takes at most 30% of the overall parsing time.
The benchmarks were run on four different architectures:
- AMD Ryzen 9900X (Fedora 43)
- Apple M4 (Fedora 41)
- Intel 285 (Fedora 42)
- IBM Power10 (RHEL 10)
C grammar results: 1.5M lines (100K sieve functions)
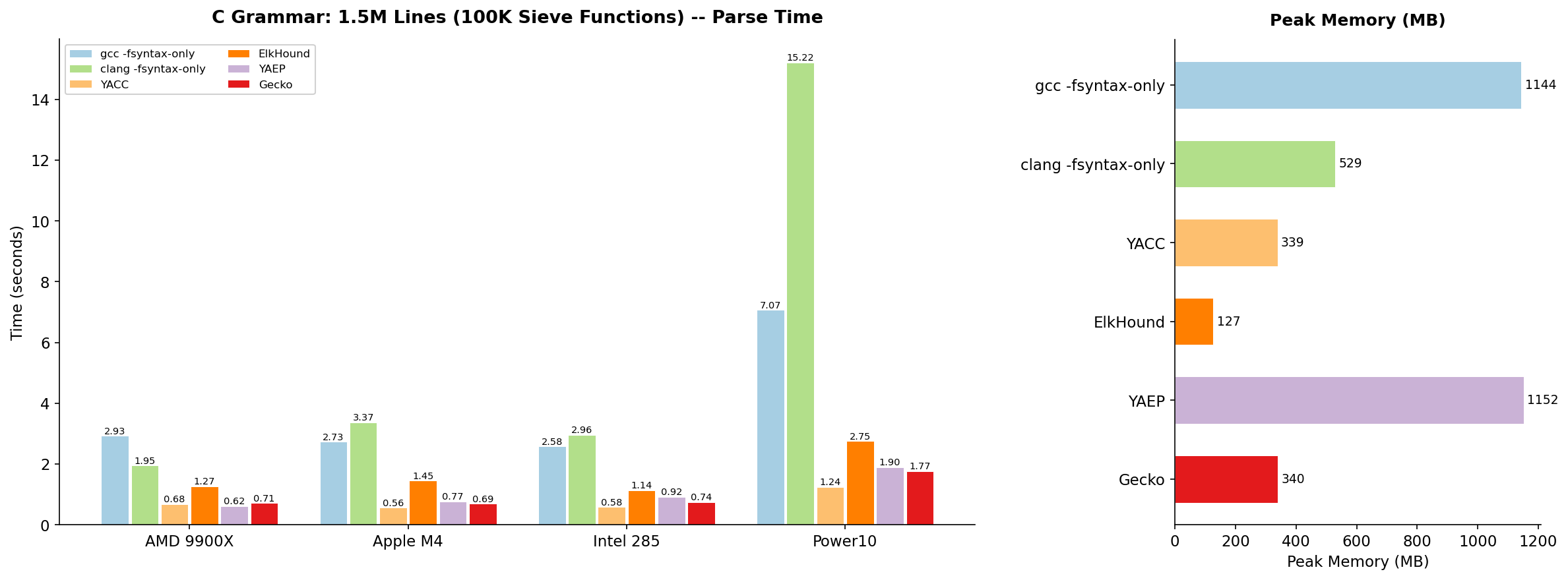
On this test, YAEP has unusually good results because it uses dynamic programming that speeds up parsing of files with repeating patterns. The second test (whole old GCC code as one file) is more representative of real-world parsing.
C grammar results: ~500K lines (whole old GCC)
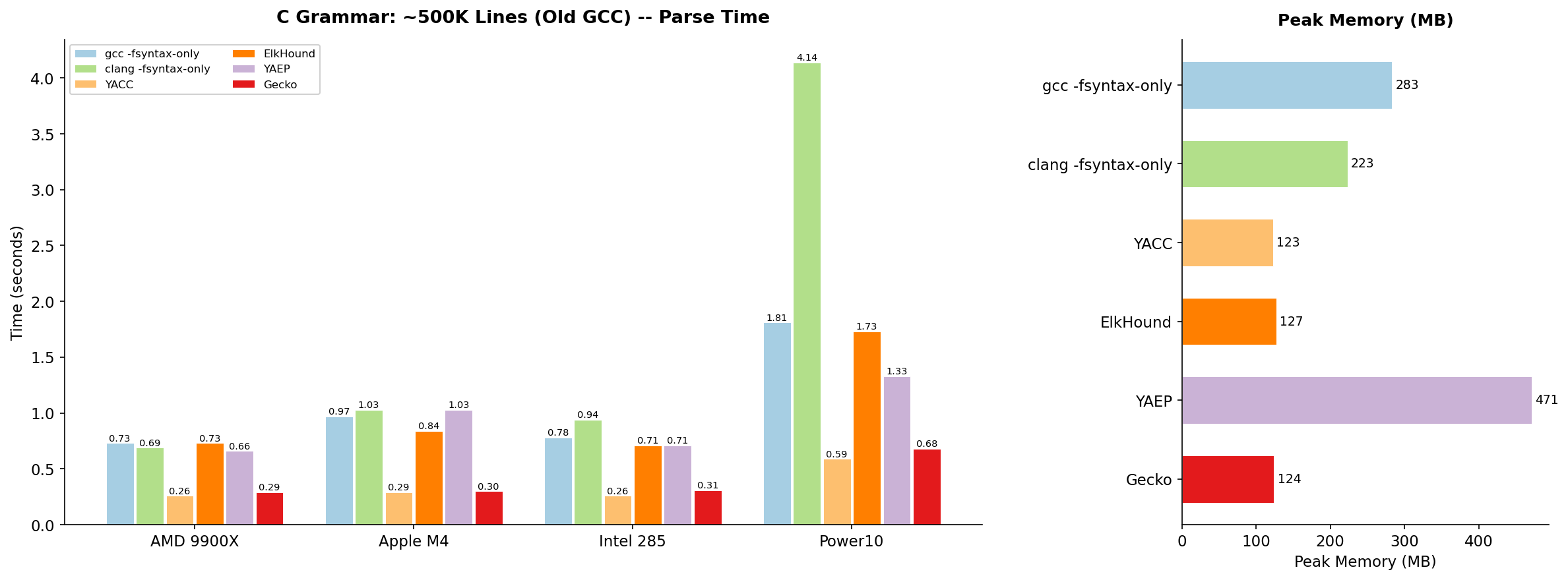
This is the more interesting benchmark. On realistic C code:
- Gecko is only 5–12% slower than YACC across all architectures, while handling a grammar that YACC cannot even accept (the ambiguous version)
- Gecko is 2–2.5x faster than ElkHound and uses comparable memory
- Gecko is 2–3x faster than YAEP and uses 3–4x less memory
- Gecko can parse roughly 2 million lines of C per second on an AMD 9900X
To put this in perspective: Gecko parses the entire old GCC source
tree in 0.29 seconds on modern hardware. The numbers for gcc
-fsyntax-only and clang -fsyntax-only, which only do fast
hand-written recursive descent parsing and basic semantic analysis,
show that parsing is not the bottleneck of the compilers. A 10% Gecko
parser slowdown will not be critical.
Highly ambiguous grammar
For the truly ambiguous grammar E = E + E | a with input a(+a){200}
(200 plus operators), Gecko’s GLR engine shows its strength:
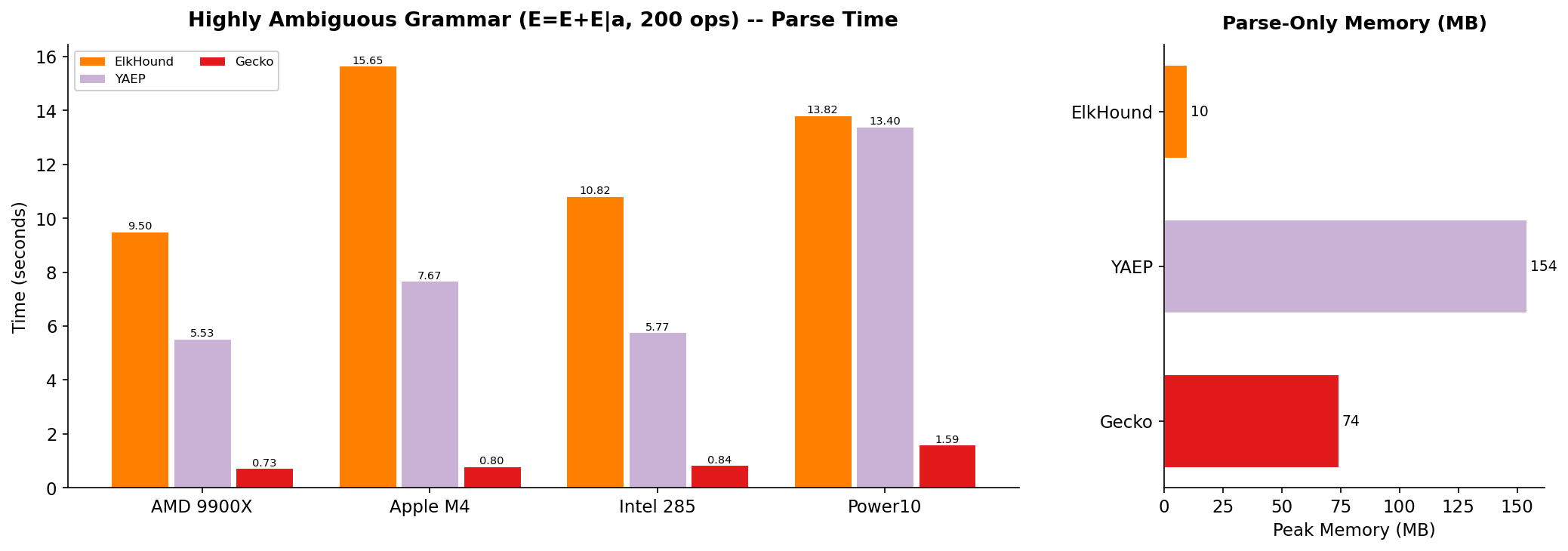
Gecko is approximately 13x faster than ElkHound and 7.5x faster than YAEP on this test. This demonstrates that Gecko’s stack merging technique works extremely well even under heavy ambiguity (see the next section).
Note: YAEP and Gecko generate AST for the test while ElkHound generates nothing and works only as a recognizer.
How Gecko works inside
Understanding Gecko’s internal architecture helps explain its performance characteristics.
Grammar analysis
When you call gp_parse_grammar or gp_read_grammar, Gecko performs
several analysis passes:
- Symbol classification –determine which symbols are terminals and which are nonterminals
- Empty detection –identify nonterminals that can derive the empty string
- Accessibility analysis –verify all nonterminals are reachable from the start symbol
- Terminal derivation –verify all nonterminals can eventually derive terminal strings
- Loop detection –detect nonterminals involved in cycles (A =>* A)
- FIRST/FOLLOW set computation –via fixed-point iteration, used for SLR set construction
In strict mode (strict_p = true), Gecko will report errors for
unreachable nonterminals, nonterminals that can’t derive terminals, and
grammar loops.
SLR set construction
After analyzing grammar, Gecko constructs SLR(1) sets (also known as LR(0) item sets with SLR lookaheads). Each set contains a collection of LR items (a rule plus a position within that rule). LR items are memoized –each unique (rule, position) pair exists as exactly one object in memory.
Each SLR set has:
- A goto map: for each nonterminal, which set to transition to
- An action map: for each terminal, what actions to take (shift, reduce, or both)
Conflicts in the action map (shift-reduce or reduce-reduce) are resolved using operator precedence and associativity declarations, exactly as in YACC. Conflicts that cannot be resolved this way are left as multiple actions. This is where GLR parsing takes over.
Setting the debug level to more than 2 before calling
gp_parse_grammar or gp_read_grammar prints SLR sets, actions, and
goto maps. Conflicts in the output are marked with !. This debug
information is useful for identifying where ambiguity can occur and
for modifying the grammar as needed.
I initially tried building SLR sets on demand during parsing, but I found that for the C grammar, parsing even small files (e.g., the sieve test) results in building practically all possible SLR sets. So I switched to building all SLR sets at once, which makes sense since building all SLR sets for the C grammar takes less than 1ms on an AMD 9900X.
The parsing algorithm
Gecko’s GLR parser uses a two-tier architecture that is key to its performance:
Single-stack fast path. When there is exactly one parsing stack and exactly one possible action for the current token, Gecko runs a tight inner loop with no extra allocations. This is the common case for unambiguous grammars and makes Gecko nearly as fast as a hand-coded LALR(1) parser. This is why Gecko achieves speeds within 5–10% of YACC on unambiguous grammars –for most tokens, it’s doing essentially the same work.
Multi-stack path. When ambiguity or unresolved conflicts create multiple possible actions, Gecko forks the stack and maintains multiple parsing paths simultaneously. Each stack independently processes shifts and reduces. Stacks that reach a dead end (no valid action) are discarded.
Stack merging. When two stacks have identical state sequences (i.e., they represent different parse trees but have arrived at the same parsing configuration), they are merged. The parse tree nodes from both stacks are combined using the user-configurable merge function. This prevents the exponential blowup that would otherwise occur with ambiguous grammars.
Garbage collection
During parsing, Gecko periodically performs garbage collection of unreachable parse tree nodes. This uses a mark-sweep algorithm with a bitmap for marking. The GC threshold is adaptive –it runs more frequently when many nodes are being created and less frequently when parsing is proceeding smoothly.
This is important for keeping memory consumption bounded during the parsing of long inputs, especially with ambiguous grammars where many intermediate nodes are created and then become unreachable as stacks are merged or discarded.
Building and installing
Getting started with Gecko is straightforward:
cd gecko
make # Build (requires GCC, YACC, AR)
make test # Run tests (requires Flex, GCC with ASAN/UBSAN)
make bench # Run benchmarks (requires YACC/Bison, GCC, Clang)
make install # Install to /usr/local
make PREFIX=/usr install # Or install to a custom prefix
After installation, gecko.h goes to $PREFIX/include and libgecko.a to
$PREFIX/lib. Link your program with -lgecko.
To run the ElkHound benchmarks, pass the ElkHound build directory:
make bench ELKHOUND_DIR=/path/to/elkhound
Design philosophy
Gecko reflects several deliberate design choices.
I preferred simplicity over generality. Gecko doesn’t try to be a framework for arbitrary semantic analysis. It produces ASTs and gets out of the way. If you need more complex semantic processing, do it in a separate pass over the AST.
Performance comes through specialization. The single-stack fast path means that for the common case (unambiguous input with an unambiguous grammar region), Gecko does no more work than YACC. The GLR machinery only kicks in when it’s actually needed.
Error recovery should be a fundamental parser feature, not an afterthought that grammar authors have to implement manually. That is why Gecko’s recovery is fully automatic.
By being a library rather than a code generator, Gecko avoids the build complexity, debugging difficulty, and inflexibility that come with generated parsers.
When to use Gecko
Gecko is a good fit when:
- You need to parse a context-free grammar that may have ambiguities
- You want good error recovery without spending days adding
errorrules to your grammar - You need a fast parser but don’t want to write one by hand
- You want to embed a parser in a larger C application
- You need operator precedence handling without writing precedence cascades
- Your grammar might change at runtime or you need multiple grammars
Gecko might not be the best choice when:
- You need sophisticated semantic actions during parsing (Gecko uses primitive rule guards instead)
- You need minimal-cost translations for highly ambiguous grammars or you need a guarantee that parsing complexity is no more than quadratic in input length (consider YAEP)
- You need a parser in a language other than C (Gecko is C-only)
Getting the code
Gecko is open source under the MIT license. The source code, tests, and benchmarks are available on GitHub:
https://github.com/vnmakarov/gecko
Conclusion
Gecko demonstrates that generalized parsing doesn’t have to mean slow parsing. By combining a GLR algorithm with a single-stack fast path, and adaptive garbage collection, Gecko achieves speeds within 5–10% of YACC on unambiguous grammars while handling the full class of context-free grammars. Its automatic error recovery eliminates one of the most painful aspects of working with traditional parser generators.
At 3,700 lines of C and 90KB of compiled code, Gecko is small enough to understand and fast enough for production use. The final result is quite satisfactory, though I expect to continue improving it as new use cases and requirements arise.